Code is text people type into files. The compiler reads the code out of the files to translate it into a lower level language or set of instructions that a computer can run. People have a hard time working with the low level stuff so we use programming languages as a simpler intermediate way of describing programs to the compiler, but more importantly, also other people. Of course the compiler doesn’t care much about how you write your program. The compiler tolerates all the “useless” extras like whitespace and comments and fancy abstractions you throw into the code. My point is that the code is meant to be understood by people more so than machines.
Easy to read code is especially important when it’s a business’s bread and butter. There are only so many hours in a day a developer can spend working on a piece of software so it makes sense to focus the developer’s efforts on value generating activities like writing new code or fixing bugs, to move the business forward faster. Time spent trying to figure out existing code is a cost the business will want to minimize.
What I’ll talk about in this post are techniques developers can use to make their code easier to read and therefore easier to “service”. I expect you’ll know about many of these techniques but I’m hoping you’ll see something new. I made a GitHub repo you can use to follow the code as it evolves. Take a look at the initial unmodified code by checking out tag “Initial”.
First, a car analogy
Have you ever changed you car’s oil on your own? The basic idea is to open a plug somewhere on the bottom of your car’s oil reservoir to let out all the old oil, then put the plug back, and finally pour new oil into the oil reservoir. Oh, and usually you’ll want to change the oil filter while you’re at it.
Suppose you know what’s involved in an oil change and maybe your friend is asking you to change the oil in their car. It’s a car you’re not familiar with. Would you be able to do it without reading the car’s manual or watching a YouTube video? It may not be obvious because car manufacturers each have their own way of designing and organizing the car’s components inside the engine bay and engine designs may vary wildly. You may be able to figure it out regardless of what you find when you pop the hood but I think you’ll probably agree the chances of this oil change going well approach 100% if the car manufacturer choses to implement the following:
- Common conventions. Even before you pop the hood you’ve probably got some idea of what to expect. There should be some kind of oil cap you can remove on the top of the engine. This is where for you’ll add new oil. There should be some kind of oil plug on the bottom of the reservoir. As for the oil filter… well let’s hope we spot it somewhere.
- Labels. Maybe you’re looking at the underside of the engine bay and you come across what looks like a bolt with a label next to it that says “Oil reservoir plug. Do not overtighten”. Ok, you’ve got this. This simple label just removed any doubt you may have had about whether or not this is the oil reservoir plug you need to remove.
- Good design. Imagine the car manufacturer placed the oil filter in a spot you can’t easily reach. Maybe you need to remove other components just to reach the oil filter.
- Inline documentation. Changing oil in a car is a pretty common reason for people to be poking around the engine bay. Maybe there’s a plaque there that gives a brief description of the process and explains were you can find the key elements you need to complete the task: the oil cap on the engine, the plug for the reservoir, the oil filter, etc. Maybe there’s even a few small images that show you what you need to do.
The way you choose to implement your code can have a significant impact on how serviceable it is, just as the way a car manufacturer’s implementation of their engine bay may make the car easy or difficult to service.
Common conventions
There are a lot of common coding conventions you can follow that will make it easier for developers to know where to find things in your application. For example prefixing private variables with an underscore is pretty common. In an ASP.NET Core application it’s common to use a “Startup” class that serves as a place to register and configure types and services as well as configure the HTTP request pipeline. The Cars API uses the “Startup” class as per the convention.
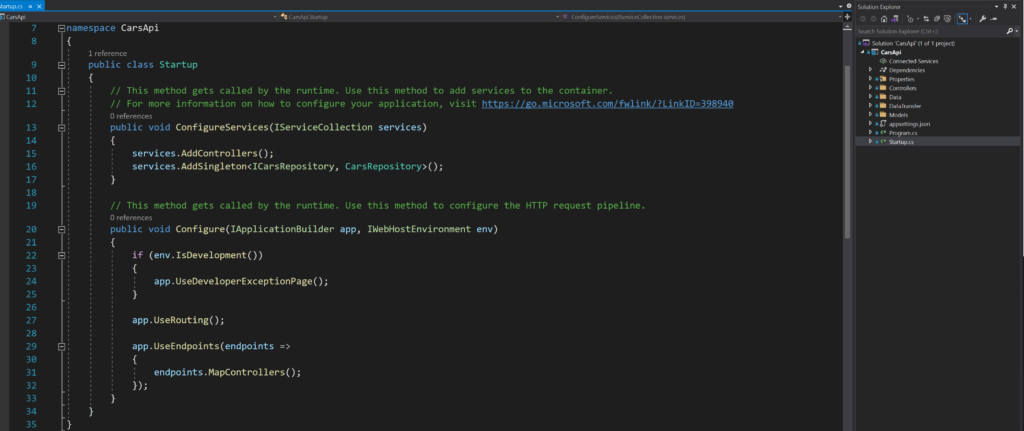
There’s also syntax conventions and naming conventions. For example in C# method names are usually capitalized, interfaces start with the letter “I”, etc.
Labels
Use nullable types
Checkout tag “Nullable” in the CarsApi repository.
Let’s take a look at ICarsRepository. It doesn’t make sense for method AddCar to ever accept a null but the method signature doesn’t communicate this. Probably nobody would even think to pass a null in there but still… Similarly, it’s not clear if method GetCarByVin allows null input. Methods GetCar and GetCarByVin say they return a Car object but it’s not clear if or when they may or may not return null. What if the car is not found for example? We’d need to look at the implementation to find this information. That’s not very clear and there’s a better way.
public interface ICarsRepository
{
void AddCar(Car car);
IEnumerable<Car> GetAllCars();
Car GetCar(int id);
Car GetCarByVin(string vin);
}
Turning on the nullable annotation context feature is perhaps one the simplest ways to improve clarity here, though there are others. It’s turned on in the project file as shown below.
<Project Sdk="Microsoft.NET.Sdk.Web">
<PropertyGroup>
<TargetFramework>net5.0</TargetFramework>
<Nullable>enable</Nullable>
</PropertyGroup>
</Project>
After turning on the nullable annotation context for this project the compiler spits out some warnings that locate places the code is not clear about data nullability.
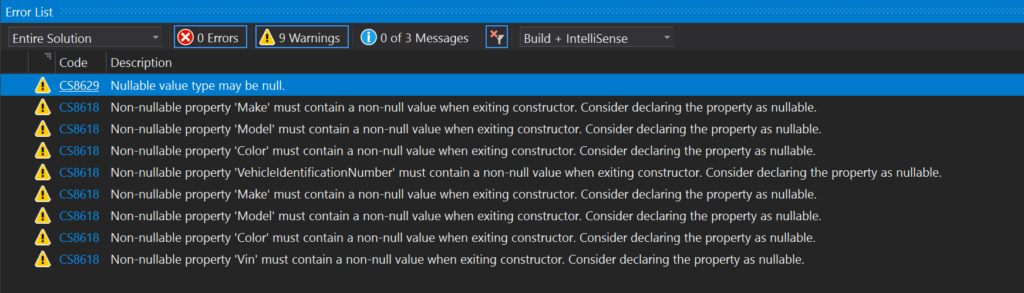
I addressed all these warnings but show only the revised ICarsRepository below. Method AddCar didn’t change but because the nullable annotation context has been enabled and the type Car isn’t declared as nullable (ex. it’s not “Car?”) it now communicates the non-null input intent. Similarly method GetCarByVin shows that it doesn’t accept null input. Methods GetCar and GetCarByVin now show that null is a possible return value. They don’t however tell us what it means when the method returns null. We’ll improve this even further later but for now it’s fairly conventional to assume these methods return null only when the car is not found.
public interface ICarsRepository
{
void AddCar(Car car);
IEnumerable<Car> GetAllCars();
Car? GetCar(int id);
Car? GetCarByVin(string vin);
}
We can see another benefit of the nullable annotation context in method CarsController.GetAllCars which used to look like this.
[HttpGet]
public IActionResult GetAllCars()
{
var cars = _carsRepo.GetAllCars();
if (cars == null)
{
return Ok(new List<Car>());
}
else
{
return Ok(cars);
}
}
Thanks to the nullable annotations context it’s now clear that the repository will never return null so the null check can be removed entirely, simplifying the code significantly. Note, it’s not that it no longer returns null, it never did but the developer didn’t know or didn’t bother to check so he or she threw in a null check. By the way this is a very common scenario I’ve come across in my experience – the unnecessary null check. Here’s the simplified version.
[HttpGet]
public IActionResult GetAllCars()
{
var cars = _carsRepo.GetAllCars();
return Ok(cars);
}
Name your variables
Checkout tag “Names” in the CarsApi repository.
This one is pretty obvious. Using variable names like “c” and “d” doesn’t promote clarity. Though it’s popular to use variables like this in LINQ queries I often go for a more explicit variable name anyway. Let’s improve method CarsController.CreateCar by replacing “c” with “existingCarModel” and replacing “m” with “carModelToCreate”. Ignore the exception for now. We’ll deal with that later.
[HttpPost]
public IActionResult CreateCar([FromBody] CarForCreateDto carForCreate)
{
try
{
ValidateCarForCreate(carForCreate);
}
catch (Exception e)
{
return BadRequest("Invalid input. " + e.Message);
}
var carModelToCreate = MapToModel(carForCreate);
var existingCarModel = _carsRepo.GetCarByVin(carModelToCreate.Vin);
IActionResult response;
if (existingCarModel != null)
{
response = BadRequest("Car with the given VIN already exists.");
}
else
{
_carsRepo.AddCar(carModelToCreate);
response = NoContent();
}
return response;
}
Use comments
Checkout tag “Comments” in the CarsApi repository.
Also pretty obvious. Some developers think that comments clutter the code and I agree this can happen but I’ve rarely seen it. Most often I see a lack of comments which I’d argue is probably worse. I like to drop lots of comments in my code to either summarize a section of code for the reader or to explain why I did something a certain way. Sometimes I’ll even explicitly point out code that may look like a typo or mistake to let the reader know that I know it looks wonky but it’s not a mistake. Let’s add some life to method CarsController.CreateCar from above.
[HttpPost]
public IActionResult CreateCar([FromBody] CarForCreateDto carForCreate)
{
// Validate the input
try
{
ValidateCarForCreate(carForCreate);
}
catch (Exception e)
{
return BadRequest("Invalid input. " + e.Message);
}
// Map the input to a model
var carModelToCreate = MapToModel(carForCreate);
// Check to see if there's already a car with the same
// VIN in the data store. We don't want duplicates.
var existingCarModel = _carsRepo.GetCarByVin(carModelToCreate.Vin);
IActionResult response;
if (existingCarModel != null)
{
// The input is a duplicate car. Fail.
response = BadRequest("Car with the given VIN already exists.");
}
else
{
// The input is unique. Proceed with car creation.
_carsRepo.AddCar(carModelToCreate);
response = NoContent();
}
return response;
}
Use named method arguments
Checkout tag “Arguments” in the CarsApi repository.
It’s not a big deal in the simple methods you see in this sample application but often in real life you’ll encounter methods with many parameters and it’s not clear at a glance what each of the parameters means. I find it often helps to explicitly name the method arguments to help the reader understand the reason the argument is being passed to the method. See the use of named parameters below in method CarsController.MapToModel. Again, in this case it’s not helping a whole lot but if the names of the variables being passed to the method were more obscure this would definitely promote clarity.
private Car MapToModel(CarForCreateDto carDto)
{
return new Car(
make: carDto.Make!,
model: carDto.Model!,
year: carDto.Year!.Value,
color: carDto.Color!,
vin: carDto.VehicleIdentificationNumber!
);
}
Good design
Don’t abuse exceptions
Checkout tag “Exception” in the CarsApi repository.
Method CarsController.ValidateCarForCreate throws an exception if there’s an problem with the input. The calling code wraps the call to ValidateCarForCreate in a try-catch block and assumes that when an exception occurs, it’s because of validation. Of course, the validation code could throw a more specific exception instead of the base Exception but really we should avoid throwing an exception at all for this purpose. The method signature for ValidateCarForCreate doesn’t communicate the fact that it returns data. If it returned information through the method’s return value things would be much clearer. Let’s change it to return data via the return value. Start by writing a result class to represent the validation result.
private class ValidationResult
{
public bool IsValid { get; set; }
public string ErrorMessage { get; set; }
private ValidationResult(bool isValid, string errorMessage)
{
IsValid = isValid;
ErrorMessage = errorMessage;
}
public static ValidationResult Valid() => new ValidationResult(true, string.Empty);
public static ValidationResult Invalid(string errorMessage) => new ValidationResult(false, errorMessage);
}
This result class is not very specific so it could be used for other validations elsewhere in the application. It carries a success or a failure. When it carries a failure the ErrorMessage property holds the value of the error message. For brevity I won’t show the updated validation method but you can assume it returns a failed validation result object in all cases it used to throw an exception. Also, it returns a successful validation result object when the input is valid. The updated method CarsController.CreateCar is shown below. Notice that as we refactor it, it’s getting both easier to read and shorter.
[HttpPost]
public IActionResult CreateCar([FromBody] CarForCreateDto carForCreate)
{
// Validate the input
var validationResult = ValidateCarForCreate(carForCreate);
if (!validationResult.IsValid)
return BadRequest("Invalid input. " + validationResult.ErrorMessage);
// Map the input to a model
var carModelToCreate = MapToModel(carForCreate);
// Check to see if there's already a car with the same
// VIN in the data store. We don't want duplicates.
var existingCarModel = _carsRepo.GetCarByVin(carModelToCreate.Vin);
IActionResult response;
if (existingCarModel != null)
{
// The input is a duplicate car. Fail.
response = BadRequest("Car with the given VIN already exists.");
}
else
{
// The input is unique. Proceed with car creation.
_carsRepo.AddCar(carModelToCreate);
response = NoContent();
}
return response;
}
Minimize nesting
Checkout tag “Nesting” in the CarsApi repository.
This is probably one of the most important guidelines. When you’re digging though multiple levels of nested if statements and loops it’s way too easy to get lost and misunderstand what you’re seeing on screen. Ideally you’ll want the code to be as sequential as possible. One technique that can help with this is called “early return”. When applicable you can use it in place of otherwise complex if-else statements. See below for a simplified version of CarsController.CreateCar.
[HttpPost]
public IActionResult CreateCar([FromBody] CarForCreateDto carForCreate)
{
// Validate the input
var validationResult = ValidateCarForCreate(carForCreate);
if (!validationResult.IsValid)
return BadRequest("Invalid input. " + validationResult.ErrorMessage);
// Map the input to a model
var carModelToCreate = MapToModel(carForCreate);
// Check to see if there's already a car with the same
// VIN in the data store. We don't want duplicates.
var existingCarModel = _carsRepo.GetCarByVin(carModelToCreate.Vin);
if (existingCarModel != null)
return BadRequest("Car with the given VIN already exists.");
// The input is unique. Proceed with car creation.
_carsRepo.AddCar(carModelToCreate);
return NoContent();
}
Don’t abuse null
Checkout tag “NullReturn” in the CarsApi repository.
It’s time to revisit the ICarsRepository. When the nullable annotation context was enabled method GetCarByVin became clearer because it made it easy to tell from the method signature that the method could possibly return null. It just didn’t communicate the conditions under which it could return null which was a bit of a bummer. One way to address this is to use an explicit result object much the way a result object was used to communicate the results of the validation operation earlier. Truthfully, what this really comes down to is cutting null out of the picture. The code will no longer signal information back to the caller by returning null. Here’s how the custom result could be implemented.
public class CarFetchResult
{
public bool IsFound { get; }
public Car? Car { get; }
private CarFetchResult(bool isFound, Car? car)
{
IsFound = isFound;
Car = car;
}
public static CarFetchResult Found(Car car) => new CarFetchResult(true, car);
public static CarFetchResult NotFound() => new CarFetchResult(false, default);
}
The result carries a Car object only when IsFound is true. Now let’s see the revised ICarsRepository implementation.
public interface ICarsRepository
{
void AddCar(Car car);
IEnumerable<Car> GetAllCars();
CarFetchResult GetCar(int id);
CarFetchResult GetCarByVin(string vin);
}
Notice that none of the inputs or outputs are nullable now which is a simplification in itself; nulls are never accepted and nulls are never returned. The calling code needs only to check the IsFound property of the result to determine whether or not the Car was found, which actually ends up making the calling code clearer as a bonus. See below.
[HttpPost]
public IActionResult CreateCar([FromBody] CarForCreateDto carForCreate)
{
// Validate the input
var validationResult = ValidateCarForCreate(carForCreate);
if (!validationResult.IsValid)
return BadRequest("Invalid input. " + validationResult.ErrorMessage);
// Map the input to a model
var carModelToCreate = MapToModel(carForCreate);
// Check to see if there's already a car with the same
// VIN in the data store. We don't want duplicates.
var carFetchResult = _carsRepo.GetCarByVin(carModelToCreate.Vin);
if (carFetchResult.IsFound)
return BadRequest("Car with the given VIN already exists.");
// The input is unique. Proceed with car creation.
_carsRepo.AddCar(carModelToCreate);
return NoContent();
}
Inline documentation
Comment blocks
Checkout tag “CommentBlock” in the CarsApi repository.
At my current place of work I’m infamous for laying down large comment blocks like the one below in CarsController.MapToModel. I call this inline documentation because it doesn’t just talk about the code itself; it provides insights into why it was implemented the way it was. I find this helps in code reviews and other unexpected situations. For example knowing why code was written the way it was may be helpful when refactoring. Reading about what was going on in the author’s head at the time they wrote the code you’re trying to refactor can give you the confidence you need to change it or give you the sense you’d better leave it untouched.
private Car MapToModel(CarForCreateDto carDto)
{
// This mapping code expects the caller to have completed
// validation prior to calling this method. Mapping may
// fail if you try to map an invalid DTO. It was done this
// way to keep the validation and mapping code separate.
return new Car(
make: carDto.Make!,
model: carDto.Model!,
year: carDto.Year!.Value,
color: carDto.Color!,
vin: carDto.VehicleIdentificationNumber!
);
}
The readme file
Checkout tag “Readme” in the CarsApi repository.
Sometimes I want to explain how files and folders are organized in a project or describe how to do common maintenance like adding a new controller endpoint for example. For this kind of documentation I like to use a readme file that I place somewhere within the project. It’s useful when people know to look inside the file (and I find they rarely do but still…). Many Git tools will automatically display the contents of a readme file it finds in the repository, which helps with visibility.
